
Dynamic Routing Between Capsules
有“深度学习之父”与“神经网络先驱”之称的Geoffrey E. Hinton终于在NIPS 2017大会上发表了酝酿已久的一篇关于Capsule的论文《Dynamic Routing Between Capsules》。
摘要
Capsule是一组神经元,其活动向量表示特定类型实体或属性的实例化参数。在本文中,使用活动向量的长度来表示实体存在的概率,而其方向表示实例化参数。活跃的Capsule通过变换矩阵来预测更高级别Capsule的实例化参数。当多个预测一致时,更高级别的Capsule变得活跃。
实验表明多层Capsule系统达到MNIST的先进的性能,在识别高度重叠数字上比卷积神经网络好得多。为了达到这种效果,文中使用了迭代的Routing-by-agreement机制:低级别的Capsule更倾向于将输出发送到其预测与相应活动向量的标量积更大的高级别Capsule。
引言
人类视觉通过一系列注视点来获取物体对象的高解析度特征,而忽略无关细节。人类在识别人脸时,并不是将图像的所有信息输入大脑,而是提取其中的特征点。
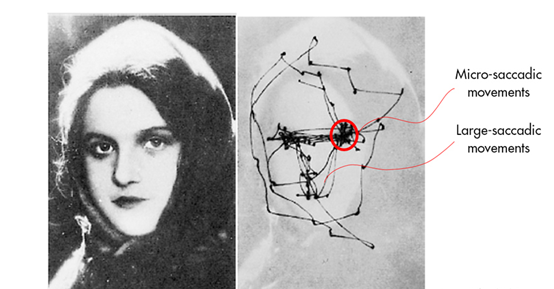
文中假设我们的多层视觉系统对于每个注视点创建了某种类似于解析树的东西。每层都被分为许多组的神经元被称为“Capsule”,而解析树中的每个节点都对应一个活跃的Capsule。通过迭代的路由过程,每个活跃的Capsule会选择高层次的Capsule作为它在树中的父母节点。对于高层次的视觉系统,这种迭代过程会解决为整体分配部分的问题。
Routing-by-agreement路由机制比“Max-pooling”更有效,后者在局部池中忽略了除最活跃的特征探测器以外的所有神经元。
Capsule的向量输入与输出的计算
本文使用了一个非线性的压扁(squashing)函数,来保证输入的短向量会缩小到接近0而长向量只会缩小到微微小于1。
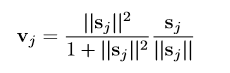
对Capsule j的输入向量sj,首先计算得到它的单位向量,如果sj的长度即2- 范数比1小的多,那么这个单位向量就会压扁到接近0。反之如果长度很大那么系数会接近于1。vj为Capsule j的输出向量。
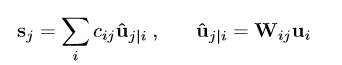
每个Capsule j的输入向量sj由上一层的所有预测向量uj|i加权求和得到,而uj|i则通过变换矩阵Wij与上一层Capsule的输出ui相乘得到。
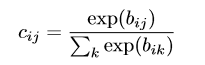
cij是由迭代的动态路由过程决定的连接系数,通过“routing softmax”得到。“routing softmax”的初始bij则为Capsule i应该连接Capsule j的log先验概率。
路由算法如下

边际损失

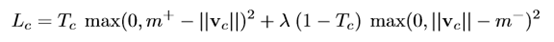
阈值m+和m-分别为0.9和0.1,意味着当向量vc长度大于0.9或小于0.1时损失会被忽略。
CapsNet结构
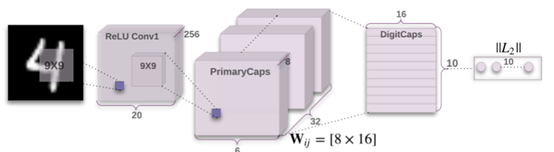
从左侧输入一张图片,用9*9的卷积核进行特征提取,因此紧接输入的那一层其实是一个卷积层。
卷积层提取特征后作为输入送入PrimaryCaps,PrimaryCaps是一个卷积 Capsule层,里面有32个通道,也就是一层里面有3266个capsule(每个通道有66个Capsule),其中每个通道中每个Capsule输出一个8维向量,一个通道的输出向量就是66*8。
PrimaryCaps和DigitCaps之间还有一个权重矩阵Wij,代表Capsule i 和Capsule j 的输出向量(8维和16维)之间的权重。同一个通道里的Capsule共享相同的权重。接着PrimaryCaps的是一个DigitCaps,这个可以看做是一个预测层,共有10个Capsule,每个Capsule对应0~9共10个数字,然后每个Capsule的输出是一个16维的向量。
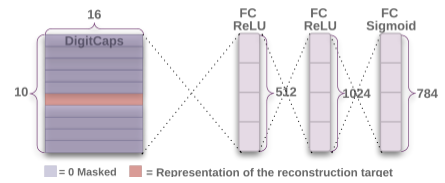
解码器用于将DigitCaps里正确数字对应的Capsule向量,通过三层全连接模型,重新构建出输入的数字图片。重构损失由与原像素强度的平方差之和定义,并且有一个为0.0005的系数以确保在训练过程中不会过度影响边际损失。

最后的实验结果标明DigitCaps Capsule所学习到的表达具有更强大鲁棒性,在未进行对自由变换图形训练的情况下能够较CNN更好的识别自由变换的数字。与此同时,动态路由机制保证了网络层之间传递信息过程中没有损失过多,允许高层Capsule同时受到低层多个活跃Capsule的影响,因此还能够分离高度重合的数字。