
Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift
Batch Normalization是Google于2015年在ICML论文中提出的一种用于加速深度神经网络训练的一种方法。
在训练深度神经网络时,由于训练过程中每层的连接参数都在通过反向传播不断变化,从而导致每层所学习的输入样本的分布都在发生变化。这种现象被称作Internal Covariate Shift即内部协变量位移,会随着网络的深度增加而放大。内部协变量位移的存在使得在每个训练循环中,参数都必须重调以补偿输入分布的改变,限制了更大学习速率的使用。同时易使非线性神经元如sigmoid、tanh饱和,导致深度网络的梯度消失,这致使需要谨慎小心的初始化网络的参数。
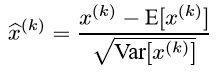
Batch Normalization通过固定每层输入的均值与方差,大大降低了内部协变量位移的影响,减少了对在参数规模上梯度和初始化的依赖,从而允许更大的学习速率,降低了发散的风险,加快了深度神经网络的训练。

与将每层输入进行Whitening即白化处理不同,Batch Normalization做出了只独立计算期望与方差的简化,不需要对每个样本都计算协方差矩阵与逆,降低了计算成本。期望与方差只使用mini-batch估计,以适应随机梯度下降算法。为了为确保每层规范化后的输入与原输入仍是恒等变换,引入了两对参数,用以保证每层的非线性学习能力。
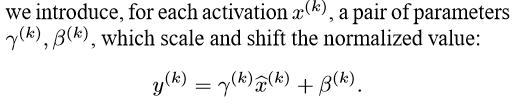
另外,Batch Normalization使得每个训练样本都与整个mini-batch相关,消除了对某个特征的强依赖,因此具有一定的Regularization效果,甚至不再需要Dropout。
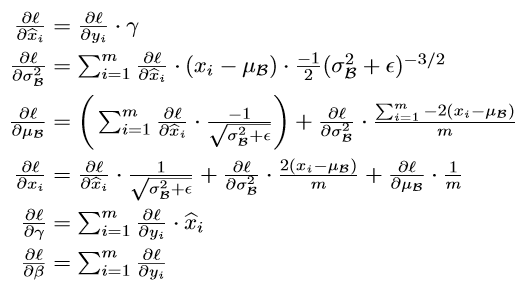
通过链式法则,可以得出Batch Normalization变换的导数。